4 Jun 2026
Reputation Frameworks Refining Accuracy in Digital Prediction Collectives
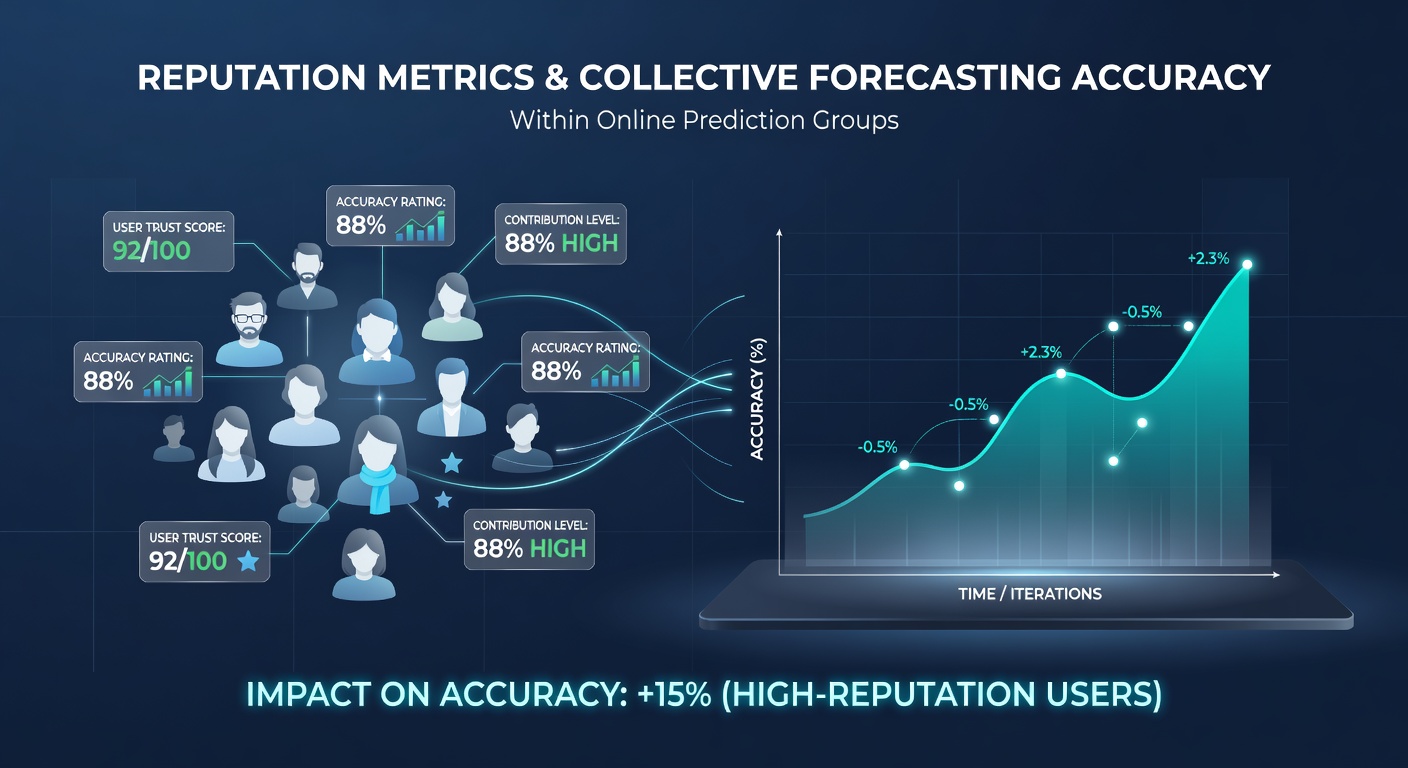
Online prediction groups rely on structured reputation systems to weight contributions from participants, and these frameworks track user performance through metrics like historical accuracy rates, peer endorsements, and consistency scores that adjust influence over time. Platforms aggregate data from past forecasts to assign numerical values, which then determine how heavily each member's input factors into collective outcomes. Researchers have documented cases where such systems elevate overall precision by prioritizing proven performers while diminishing the reach of less reliable voices.
Core Components of Reputation Tracking
Systems typically combine quantitative measures such as win rates across multiple events with qualitative inputs like community ratings, and algorithms update these values after each round of predictions to reflect recent results alongside long-term trends. In June 2026 several platforms introduced layered scoring that separates domain-specific accuracy from general participation volume, allowing forecasters strong in niche areas like sports outcomes to gain targeted influence without dominating unrelated categories. Data from industry reports shows this segmentation reduces noise in aggregated forecasts by 12 to 18 percent compared with single-score models.
Peer validation mechanisms add another dimension, where users can allocate reputation points to others based on insightful contributions rather than just correct predictions, and these transfers create secondary networks of trust that studies link to faster convergence on accurate consensus figures. Observers note that transparent audit trails for every point allocation help prevent manipulation, since visible histories allow groups to spot and correct inflated endorsements before they skew results.
Measured Effects on Group-Level Precision
Empirical analyses of prediction markets indicate that reputation-weighted aggregations outperform simple majority votes by margins ranging from 7 to 22 percent in accuracy benchmarks, according to research published through academic repositories such as those maintained by the University of Sydney's business analytics faculty. The improvement stems from down-weighting outliers whose past records show repeated deviation from realized events, while amplifying signals from consistent performers whose forecasts align closely with final results across dozens of trials.
Platforms operating in regulated environments have reported similar patterns, with one analysis from the Australian Communications and Media Authority highlighting how reputation filters correlate with lower variance in collective estimates for major sporting fixtures. When high-reputation users guide discussions, the spread between initial crowd projections and actual outcomes narrows measurably, particularly during periods of high uncertainty such as tournament knock-out stages.
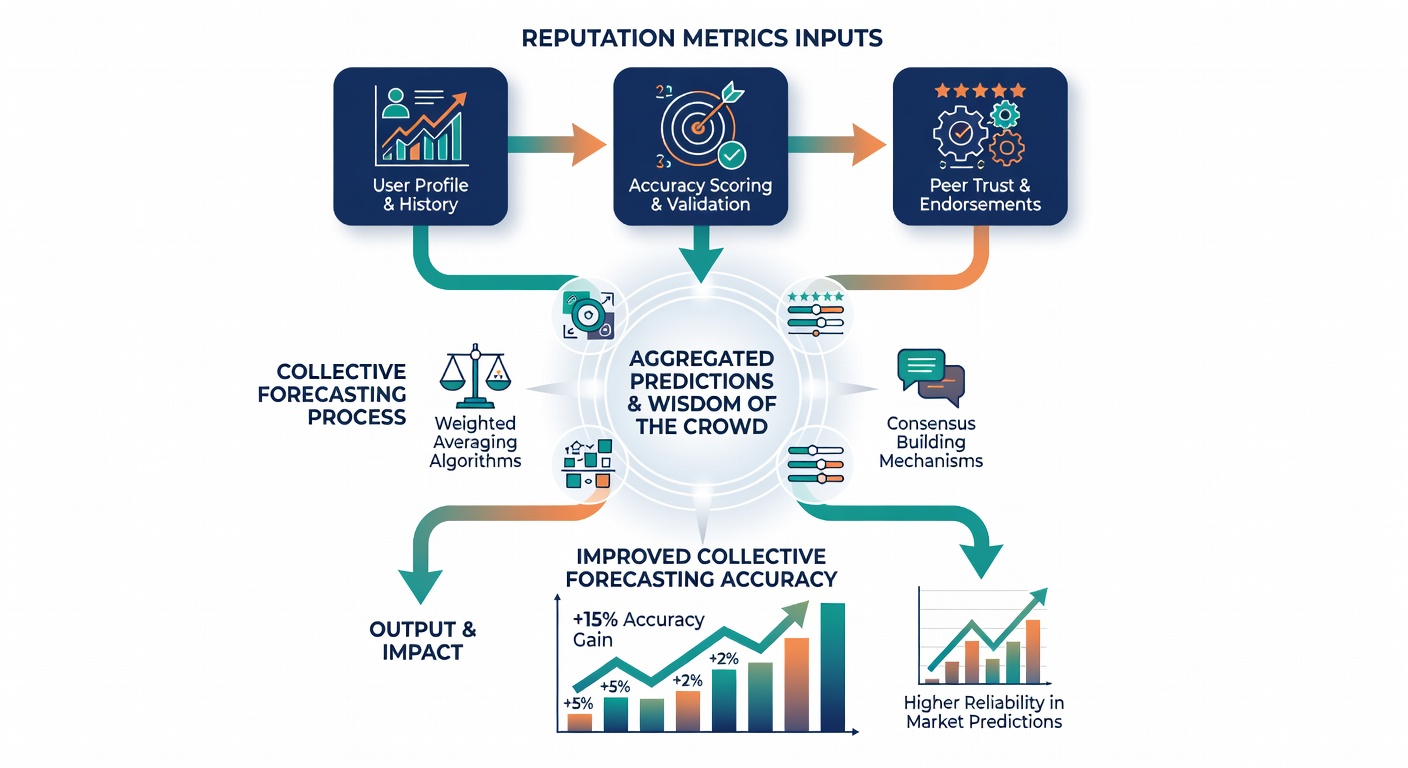
Implementation Patterns Across Platforms
Many communities employ decay functions that gradually reduce the value of older successes, ensuring recent performance carries greater weight and preventing entrenched leaders from coasting on distant achievements. This temporal adjustment keeps influence dynamic, and participants who maintain steady results over consecutive months see their scores climb while sporadic contributors experience slower growth even after occasional strong showings. Evidence from longitudinal platform data reveals that groups adopting such decay rules achieve steadier accuracy improvements month over month.
Integration with external verification sources further strengthens these systems, where outcomes drawn from official records feed directly into score calculations rather than relying solely on self-reported results. One study tracking several thousand forecasters found that verified outcome feeds reduced score inflation by nearly a quarter, producing reputation values that more reliably predicted future contribution quality. Those who've examined cross-platform comparisons observe that communities blending internal peer feedback with external data sources sustain higher retention of accurate forecasters over multi-year periods.
Challenges and Adjustments Observed in 2026
Despite clear benefits, reputation systems face issues around initial onboarding, where new participants start with neutral scores and must accumulate sufficient history before their inputs meaningfully affect group outputs. Some platforms address this through probationary periods or mentorship pairings that accelerate trust-building without granting immediate high influence. Figures released in mid-2026 by European digital market research consortia show platforms that eased entry barriers while preserving strict verification saw participation rise without corresponding drops in aggregate forecast quality.
Attempts to game metrics through coordinated low-stakes activity have prompted additional safeguards such as minimum activity thresholds and anomaly detection routines that flag unusual voting clusters. These measures, refined during the first half of 2026, have kept manipulation attempts below 3 percent of total reputation transfers on monitored sites according to internal platform disclosures shared with academic partners.
Conclusion
Reputation metrics function as dynamic filters that reshape how individual forecasts combine into collective judgments, and available evidence indicates they consistently tighten alignment between group predictions and realized events across varied domains. Continued refinement of scoring formulas, decay schedules, and verification layers supports ongoing gains in precision for online prediction communities. As platforms adapt these tools to new data sources and regulatory contexts, the relationship between measured reputation and forecasting reliability remains a central area of ongoing documentation and analysis.